Recently, H2020 INFINITECH, Europe’s flagship project for Artificial Intelligence (AI) and BigData in Digital Finance, released the first version of its Reference Architecture (RA), which is conveniently called INFINITECH-RA. INNOV-ACTS is a member of the INFINITECH consortium and one of the lead contributors in the INFINITECH-RA. The INFINITECH-RA specifies structuring principles for AI and BigData system in Digital Finance towards supporting digital finance use cases such as credit risk scoring based on, roboadvisors, personalized investment recommendations, personal finance management, fraud detection, Anti-Money Laundering (AML), as well as variety of Insurance-related use cases. Most of these use cases can be implemented based on Machine Learning (ML) algorithms that help increasing automation and knowledge extraction.
INFINITECH-RA Background and Positioning Against Other Reference Models
The development of ML uses cases for digital finance entails a series of data processing steps, which can be structured in end-to-end data management pipelines. INFINITECH-RA specifies building blocks for processing large datasets from their ingestion to the ultimate visualization of ML results. This approach is in-line with the operation of most ML platforms and tools (e.g., KNIME, Auto-SKLearn, MLBox) which facilitate the development and integration of end-to-end pipelines. INFINITECH-RA builds on popular ML concepts, as well as on best practices introduced by relevant Reference Architecture Models for the finance sector that have been introduced in the industry. Specifically, INFINITECH-RA aligns to principles and best practices introduces by Reference Architecture Models developed by prominent vendors (e.g., IBM that is a member of the INFINITECH consortium), relevant H2020 projects (e.g., H2020 FINSEC and H2020 BOOST), as well as relevant Associations such as the Big Data Value Association (BDVA).
A main value proposition of the INFINITECH-RA is its flexibility: Instead of providing a rigorous (but monolithic) structure of BigData/AI applications, it defines these applications as collections of data-driven pipelines. The latter are built based on INFINITECH components and technologies, such as ML algorithms, data ingestion techniques, anonymization techniques, encryption techniques, data virtualization techniques and more. Hence, the INFINITECH-RA provides several layered architectural concepts and a rich set of digital building blocks, which enable the development of virtually any BigData or AI application in Digital Finance.
The INFINITECH-RA aligns with BDVA’s reference model for Big Data applicationz. The latter model has horizontal layers encompassing aspects of the data processing chain, and vertical layers addressing cross-cutting issues (e.g. cybersecurity and trust). Specifically, the BDVA Reference Model is structured into horizontal and vertical concerns as follows:
- Horizontal concerns cover specific aspects along the data processing chain, starting with data collection and ingestion, and extending to data visualisation. The horizontal concerns do not imply a layered architecture. As an example, data visualisation may be applied directly to collected data (the data management aspect) without the need for data processing and analytics.
- Vertical concerns address cross-cutting issues, which may affect all the horizontal concerns. In addition, vertical concerns may also involve non-technical aspects.
Overview of The Layers of INFINITECH-RA
The INFINITECH RA defines layers to logically group components. The identified layers are:
- Data Sources: At the infrastructure level there are the source of data (database management systems, data lakes holding non-structural data, etc)
- Ingestion: A layer of data management usually associated with data import, semantic annotation, and filtering from data sources.
- Security: A layer for management of the clearance of data for security, anonymization, cleaning of data before any further storing or elaboration
- Management: A layer responsible for the data management aspects, including the persistent storage in the central repository and the data processing enabling advanced functionalities such as Hybrid Transactional and Analytical Processing (HTAP), polyglot capabilities, etc
- Analytics: A layer for AI/ML components.
- Interface: A layer for the definition data to be produced for user interfaces
- Cross Cutting: A layer with service components that provides functionalities orthogonal to the data flows (e.g. Authentication, Authorization, …)
- Data Model: A cross cutting layer for modelling and semantics of data in the data flow.
- Presentation/Visualization: A layer usually associated with the presentation applications (e.g., desktop, mobile apps, dashboards)
It should be noted that the IRA does not impose any pipelined, or sequential composition of nodes. However, it is recommended to consider each different layer and the relative components to solve specific problems of digital finance use cases.
Sample INFINITECH-RA Workflow
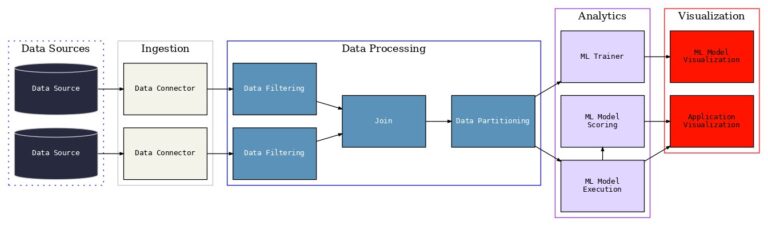
As a prominent example of its use, the INFINITECH-RA enables the design and execution of classical machine learning pipelines. Typical machine learning applications are implemented in-line with popular data mining methods like the CRISP-DM (Cross Industry Standard Process for Data Mining). CRISP-DM includes several phases, including the phases of data preparation, modelling, and evaluation. In typical Machine Learning pipelines, data are acquired from various sources and prepared in-line with the needs of the target ML model. The preparation of the data includes their segmentation into training data (i.e. data used to train the model) and test data (i.e. data used to test the model). The model is usually evaluated against the requirements of the target business application. The following illustrates how a typical machine learning pipeline can be implemented/mapped to the layers and functionalities of the INFINITECH-RA. Specifically, the following layers/parts are envisaged:
- Data Sources: At this level reside the data sources of the BigData/AI application. These may be of different types including databases, datastores, datalakes, files (e.g., spreadsheets) and more.
- Data Ingestion: At this level of the pipeline, data are accessed based on appropriate connectors. Depending on the type of the data sources, other INFINITECH components for data ingestion can be used such as data collectors and serializers. Moreover, conversions between the data formats of the different sources can take place.
- Data Management: At this level data are managed. Filtering functions may be applied and data sources can be joined towards forming integrated data sets. Likewise, other preprocessing functionalities may be applied, such as partitioning of datasets into training and test segments. Furthermore, if needed, this layer provides the means for persisting data at scale, but also for accessing it through user friendly logical query interfaces. The latter functionalities are not however depicted in the figure.
- Analytics: This is the layer where the machine learning functions (e.g., decision tree learners, regressor learners or deep neural networks) are placed. A Typical ML application entails the training of Machine Learning model based on the training datasets, as well as the execution of the learnt models based on test datasets. It may also include the scoring of the model based on the test data.
- Presentation: This is the layer where the model and its results are visualized in-line with the needs of the target application.
In coming blogs, we will illustrate practical, real-life examples of digital finance use cases that can be implemented as INFINITECH-RA compliant pipelines. Stay tuned.
Follow as on Twitter: @Infinitech_EU for updates on the INFINITECH-RA and use cases!
